-
DDL语句:数据定义语言,用来维护数据库对象
- CREATE; DESC tablename – 用于查看表的数据结构;
- DEFAULT – 设置默认值
- RENAME; ALTER TABLE; DROP;
-
DML语句:Data Manipulation Language 数据操作语言
insert --将记录插入到数据库 update --修改数据库的记录 delete --删除数据库的记录 -
DQL: select 查询语句
SQL中LTrim、RTrim与Trim的用法
LTrim、RTrim与 Trim 函数 返回 Variant (String),其中包含指定字符串的拷贝,删除前导空白 (LTrim)、尾随空白 (RTrim) 或前导和尾随空白 (Trim)。
SQL中的left函数、right函数
LEFT、RIGHT函数返回ARG最左边、右边的LENGTH个字符串,ARG可以是CHAR或BINARY STRING。
CASE WHEN
简单case函数
CASE sex
WHEN '1' THEN 'male'
WHEN '0' THEN 'female'
ELSE 'other' END
case搜索函数
CASE WHEN sex = '1' THEN 'male'
WHEN sex = '0' THEN 'female'
ELSE 'other' END
简单Case函数的写法相对比较简洁,但是和Case搜索函数相比,功能方面会有些限制,比如写判断式。还有一个需要注意的问题,Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。
- 在SQL server中自增ID不是
AUTO_INCREMENT,而是IDENTITY(1, 1)
[ID] INT NOT NULL IDENTITY(1, 1),
用一个SQL语句完成不同条件的分组
| 国家 | 性别 | 人口 |
|---|---|---|
| 中国 | 1 | 340 |
| 中国 | 2 | 260 |
| 美国 | 1 | 45 |
| 美国 | 2 | 55 |
| 加拿大 | 1 | 51 |
| 加拿大 | 2 | 49 |
| 英国 | 1 | 40 |
| 英国 | 2 | 60 |
按照国家和性别进行分组,得出结果如下:
| 国家 | 男 | 女 |
|---|---|---|
| 中国 | 340 | 260 |
| 美国 | 45 | 55 |
| 加拿大 | 51 | 49 |
| 英国 | 40 | 60 |
-- create table
CREATE TABLE `table_a` (
`id` INT(10) NOT NULL AUTO_INCREMENT,
`country` VARCHAR(100) DEFAULT NULL,
`population` INT(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
-- insert value
INSERT INTO table_A (country,sex,population) VALUES('中国',1,340);
INSERT INTO table_A (country,sex,population) VALUES('中国',2,260);
INSERT INTO table_A (country,sex,population) VALUES('美国',1,45);
INSERT INTO table_A (country,sex,population) VALUES('美国',2,55);
INSERT INTO table_A (country,sex,population) VALUES('加拿大',1,51);
INSERT INTO table_A (country,sex,population) VALUES('加拿大',2,49);
INSERT INTO table_A (country,sex,population) VALUES('英国',1,40);
INSERT INTO table_A (country,sex,population) VALUES('英国',2,60);
-- execute query
SELECT country as '国家',
SUM(CASE WHEN sex = 1 THEN population ELSE 0 END) as '男',
SUM(CASE WHEN sex = 2 THEN population ELSE 0 END) as '女'
FROM table_a
GROUP BY country
CASE中易犯的错误
CASE col_1
WHEN 1 THEN 'Right'
WHEN NULL THEN 'Wrong' -- 有问题,应该是`WHEN col_1 IS NULL`
END
When Null这一行总是返回unknown,所以永远不会出现Wrong的情况。应该选择用WHEN col_1 IS NULL。
CASE WHEN 和 IF
计算时间CASE WHEN要比IF判断快一些
UPDATE table_name
SET sex = IF(sex = 'm', 'f', 'm')
-- 底下这个更快
UPDATE table_name
SET sex =
CASE sex
WHEN 'f' THEN 'm'
ELSE 'f'
END;
日期加减函数 DATEDIFF, DATEADD
DATEDIFF: 返回跨两个指定日期的日期边界数和时间边界数, 语法:DATEDIFF ( datepart , startdate , enddate ) 用 enddate 减去 startdate
DATEADD : 返回给指定日期加上一个时间间隔后的新 datetime 值。 语法:DATEADD (datepart , number, date )
-- 本月一共有多少天
SELECT CAST(day(dateadd(dd, -1,dateadd(mm, 1, cast(CAST(year(getdate()) as VARCHAR) + '-' + CAST(month(getdate()) as VARCHAR) + '-01' as datetime)))) as INT);
-- 31
GROUP BY & HAVING 条件
向 GROUP BY 添加条件的一种更常用的方法是使用 HAVING 子句,该子句更为简单高效。
查找重复的电子邮箱:
Select Email from Person
Group by Email
Having count(Email) > 1;
优先顺序:where > group by > having > order by
p.s. HAVING后面的条件可以包含计算
日期操作 p.s. 这个是mysql里的语法
select date_add('2018-06-26',INTERVAL '5' day);
关于GROUP BY的理解
关系数据库是基于关系的,单元格中是不允许有多个值的,所以在GROUP BY 之后直接执行select * 语句就报错了,必须要聚合函数,用来输入多个数据,输出一个数据的,如cout(id),sum(number)。
因此,在GROUP BY id之后,首先生成了一个虚拟表(一个id 对应多个其他变量),如果对每个id都要使用CASE WHEN进行筛选,则需要agg(CASE WHEN … END),因为CASE WHEN 本身只会判断每个id 所对应的第一条数据,虽然可能agg函数不导致数值变化,但是加上聚合函数则保证每个id都把所有的数据匹配一遍。
窗口函数 RANK, DENSE_RANK, ROW_NUMBER
三个函数都和排名功能相关,具体地:
SELECT *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dense_ranking,
row_number() over (order by 成绩 desc) as row_number
FROM 班级
结果如下所示:
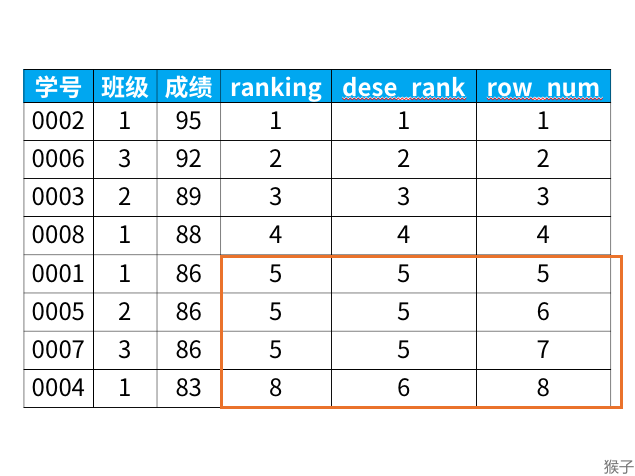
- rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
- dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
- row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
DATEDIFF , BETWEEN AND
WHERE datediff('2019-07-27',activity_date) < 30
-- 效果和下面等价
WHERE activity_date BETWEEN '2019-06-28' AND '2019-07-27'
MySQL数字的取整、四舍五入、保留n位小数
MySQL常用的四舍五入函数:
函数 说明 FLOOR(X) 返回不大于X的最大整数。 CEIL(X)、CEILING(X) 返回不小于X的最小整数。 TRUNCATE(X,D) 返回数值X保留到小数点后D位的值,截断时不进行四舍五入。 ROUND(X) 返回离X最近的整数,截断时要进行四舍五入。 ROUND(X,D) 保留X小数点后D位的值,截断时要进行四舍五入。 FORMAT(X,D) 将数字X格式化,将X保留到小数点后D位,截断时要进行四舍五入。
-- 返回不大于X的最大整数。
SELECT FLOOR(1.3); -- 输出结果:1
SELECT FLOOR(1.8); -- 输出结果:1
-- 返回不小于X的最小整数。
SELECT CEIL(1.3); -- 输出结果:2
SELECT CEILING(1.8); -- 输出结果:2
-- 返回数值X保留到小数点后D位的值,截断时不进行四舍五入。
SELECT TRUNCATE(1.2328,3); -- 输出结果:1.232
-- 返回离X最近的整数,截断时要进行四舍五入。
SELECT ROUND(1.3); -- 输出结果:1
SELECT ROUND(1.8); -- 输出结果:2
-- 保留X小数点后D位的值,截断时要进行四舍五入。
SELECT ROUND(1.2323,3); -- 输出结果:1.232
SELECT ROUND(1.2328,3); -- 输出结果:1.233
-- 将数字X格式化,将X保留到小数点后D位,截断时要进行四舍五入。
SELECT FORMAT(1.2323,3); -- 输出结果:1.232
SELECT FORMAT(1.2328,3); -- 输出结果:1.233
UNION & UNION ALL
UNION 用于合并两个或多个 SELECT 语句的结果集,并消去表中任何重复行。UNION 内部的 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
SELECT column_name FROM t1
UNION
SELECT column_name FROM t2
如果允许重复的值,请使用 UNION ALL,不消除重复行。
SELECT column_name FROM table1
UNION ALL
SELECT column_name FROM table2
DELETE 与其优化
原始的DELETE语句:
DELETE FROM delete_1 WHERE id IN (SELECT ...)
表名写为简称:
DELETE a FROM delete_1 a WHERE a.id IN (SELECT ...)
-- IN改成=也可以
DELETE a FROM delete_1 a WHERE a.id = (SELECT ...)
窗口函数总结
窗口:记录集合
窗口函数:在满足某些条件的记录集合上执行的特殊函数,对于每条记录都要在此窗口内执行函数。有的函数随着记录的不同,窗口大小都是固定的,称为静态窗口;有的函数则相反,不同的记录对应着不同的窗口,称为滑动窗口。
窗口函数和聚合函数的区别
- 聚合函数是将多条记录聚合为一条;窗口函数是每条记录都会执行,有几条记录执行完还是几条。
- 聚合函数也可以用于窗口函数。
基本用法
函数名 OVER 子句
OVER 用来指定函数执行的窗口范围,若后面括号中什么都不写,则意味着窗口包含满足 WHERE 条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下4中语法来设置窗口。
- window_name:给窗口指定一个别名。如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读;
PARTITION BY 子句:窗口按照哪些字段进行分组,窗口函数在不同的分组上分别执行;ORDER BY子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号;FRAME子句:FRAME是当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用。
按功能划分可将MySQL支持的窗口函数分为如下几类
序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
查询每个学生的分数最高的前3门课程:
ROW_NUMBER() OVER (PARTITION BY stu_id ORDER BY score)
- ROW_NUMBER():顺序排序——1、2、3
- RANK():并列排序,跳过重复序号——1、1、3
- DENSE_RANK():并列排序,不跳过重复序号——1、1、2
分布函数:PERCENT_RANK()、CUME_DIST()
给窗口指定别名:WINDOW w AS (PARTITION BY stu_id ORDER BY score)
- PERCENT_RANK(不常用)
每行按照公式(rank-1) / (rows-1)进行计算。其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数:
SELECT PERCENT_RANK() OVER w as prk
FROM scores
WHERE stu_id = 1
WINDOW w AS (PARTITION BY stu_id ORDER BY score)
- CUME_DIST
分组内小于、等于当前rank值的行数 / 分组内总行数
SELECT stu_id, score,
CUME_DIST() OVER (ORDER BY score) as cd1,
CUME_DIST() OVER (PARTITION BY lesson_id ORDER BY score) as cd2
FROM scores
WHERE lesson_id IN ('L001', 'L002')
前后函数:LAG(expr,n)、LEAD(expr,n)
返回位于当前行的前n行(LAG(expr,n))或后n行(LEAD(expr,n))的expr的值
应用场景:查询前1名同学的成绩和当前同学成绩的差值
SELECT stu_id, score,
LAG(score, 1) OVER w AS pre_score
FROM scores
WHERE lesson_id IN ('L001', 'L002')
WINDOW w AS (PARTITION BY lesson_id ORDER BY score)
头尾函数:FIRST_VALUE(expr)、LAST_VALUE(expr)
返回第一个(FIRST_VALUE(expr))或最后一个(LAST_VALUE(expr))expr的值
应用场景:截止到当前成绩,按照日期排序查询第1个和最后1个同学的分数
SELECT stu_id, lesson_id, score, create_time,
FIRST_VALUE(score) OVER w AS first_score,
LAST_VALUE(score) OVER w AS last_score
FROM scores
WHERE lesson_id IN ('L001', 'L002')
WINDOW w AS (PARTITION BY lesson_id ORDER BY create_time)
其它函数:NTH_VALUE(expr, n)、NTILE(n)
- NTH_VALUE(expr, n): 返回窗口中第n个
expr的值。expr可以是表达式,也可以是列名
应用场景:截止到当前成绩,显示每个同学的成绩中排名第2和第3的成绩的分数
SELECT stu_id, lesson_id, score,
NTH_VALUE(score, 2) OVER w AS sec_score,
NTH_VALUE(score, 3) OVER w AS thir_score
FROM scores
WINDOW w AS (PARTITION BY stu_id ORDER BY score)
- NTILE(n): 将分区中的有序数据分为n个等级,记录等级数
应用场景:将每门课程按照成绩分成3组
SELECT NTILE(3) OVER w as nf, stu_id, lesson_id, score
FROM scores
WINDOW w AS (PARTITION BY lesson_id ORDER BY score)
注意:NTILE(n)函数在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到n个并行的进程分别计算,此时就可以用NTILE(n)对数据进行分组(由于记录数不一定被n整除,所以数据不一定完全平均),然后将不同桶号的数据再分配。
聚合函数作为窗口函数
在窗口中每条记录动态地应用聚合函数(SUM()、AVG()、MAX()、MIN()、COUNT()),可以动态计算在指定的窗口内的各种聚合函数值。
SELECT stu_id, lesson_id, score
SUM(score) OVER w AS score_sum,
MAX(score) OVER w AS score_max
FROM scores
WINDOW w AS (PARTITION BY stu_id)